前言
Go语言最得天独厚的一个优势,就是并发处理能力,掌握Go Routine和Channel等这些概念的底层基本原理和使用技巧。疏通分布式并发系统开发的相关知识节点,既要能做造火箭的拧螺丝工,也要从全局的角度来认识为什么螺丝必须这么拧。以下内容来自并发编程课的学习记录。
并发编程学习矩阵
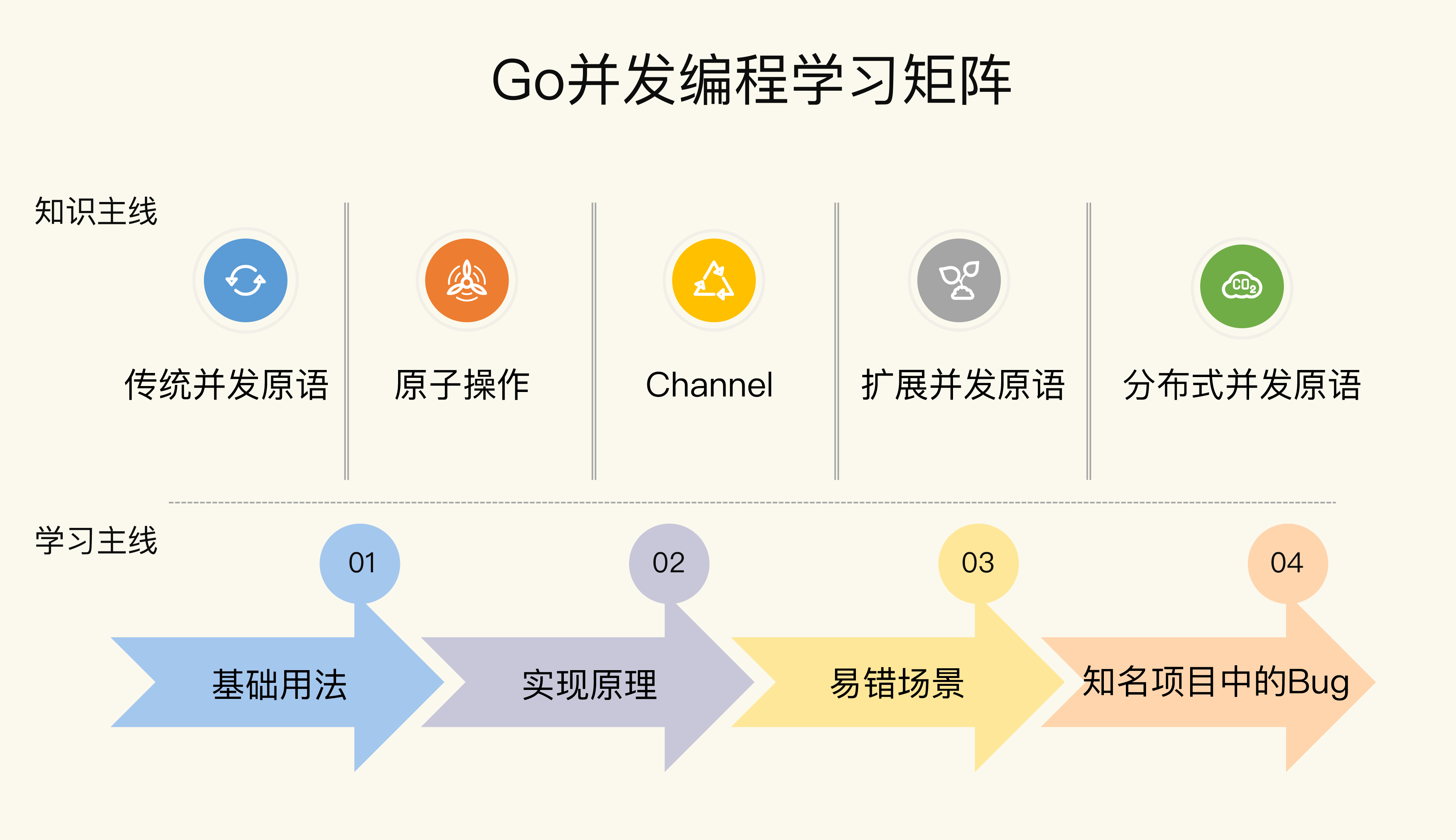
关于Go并发编程,有两条主线,分别是知识主线和学习主线。从图中可以看到,在知识主线层面,这门课程的核心内容设计了5个模块:
- 基本并发原语:在这部分,主要有Mutex、RWMutex、Waitgroup、Cond、Pool、Context等标准库中的并发原语,这些都是传统的并发原语,在其它语言中也很常见,是我们在并发编程中常用的类型。
- 原子操作:在这部分,介绍Go标准库中提供的原子操作。原子操作是其它并发原语的基础,学会了你就可以自己创造新的并发原语(Synchronization primitives)。
- Channel:Channel类型是Go语言独特的类型,因为比较新,所以难以掌握。但是别怕,我会带你全方位地学习Channel类型,你不仅能掌握它的基本用法,而且还能掌握它的处理场景和应用模式,避免踩坑。
- 扩展并发原语:目前来看,Go开发组不准备在标准库中扩充并发原语了,但是还有一些并发原语应用广泛,比如信号量、SingleFlight、循环栅栏、ErrGroup等。掌握了它们,就可以在处理一些并发问题时,取得事半功倍的效果。
- 分布式并发原语:分布式并发原语是应对大规模的应用程序中并发问题的并发类型。介绍使用etcd实现的一些分布式并发原语,比如Leader选举、分布式互斥锁、分布式读写锁、分布式队列等,在处理分布式场景的并发问题时,特别有用。
在学习主线层面,主要是四大步骤,包括基础用法、实现原理、易错场景和知名项目中的bug。通过层层递进的方式掌握每一种并发原语的实现机制和适用场景。
1、并发锁:Mutex-解决资源并发访问问题
并发访问问题,非常常见,比如多个goroutine并发更新同一个资源,像计数器;同时更新用户的账户信息;秒杀系统;往同一个buffer中并发写入数据等等。如果没有互斥控制,就会出现一些异常情况,比如计数器的计数不准确、用户的账户可能出现透支、秒杀系统出现超卖、buffer 中的数据混乱,等等,后果都很严重。这些都属于并发对临界资源的访问,临界资源必须加锁,而在Go中,采用Mutex互斥锁来控制并发访问。
互斥锁的实现机制
临界区:并发编程中需要被保护的区域。临界区就是一个被共享的资源,或者说是一个整体的一组共享资源,比如对数据库的访问、对某一个共享数据结构的操作、对一个 I/O 设备的使用、对一个连接池中的连接的调用,等等。
如果很多线程同步访问临界区,就会造成访问或操作错误,这当然不是我们希望看到的结果。所以,我们可以使用互斥锁,限定临界区只能同时由一个线程持有。
当临界区由一个线程持有的时候,其它线程如果想进入这个临界区,就会返回失败,或者是等待。直到持有的线程退出临界区,这些等待线程中的某一个才有机会接着持有这个临界区。
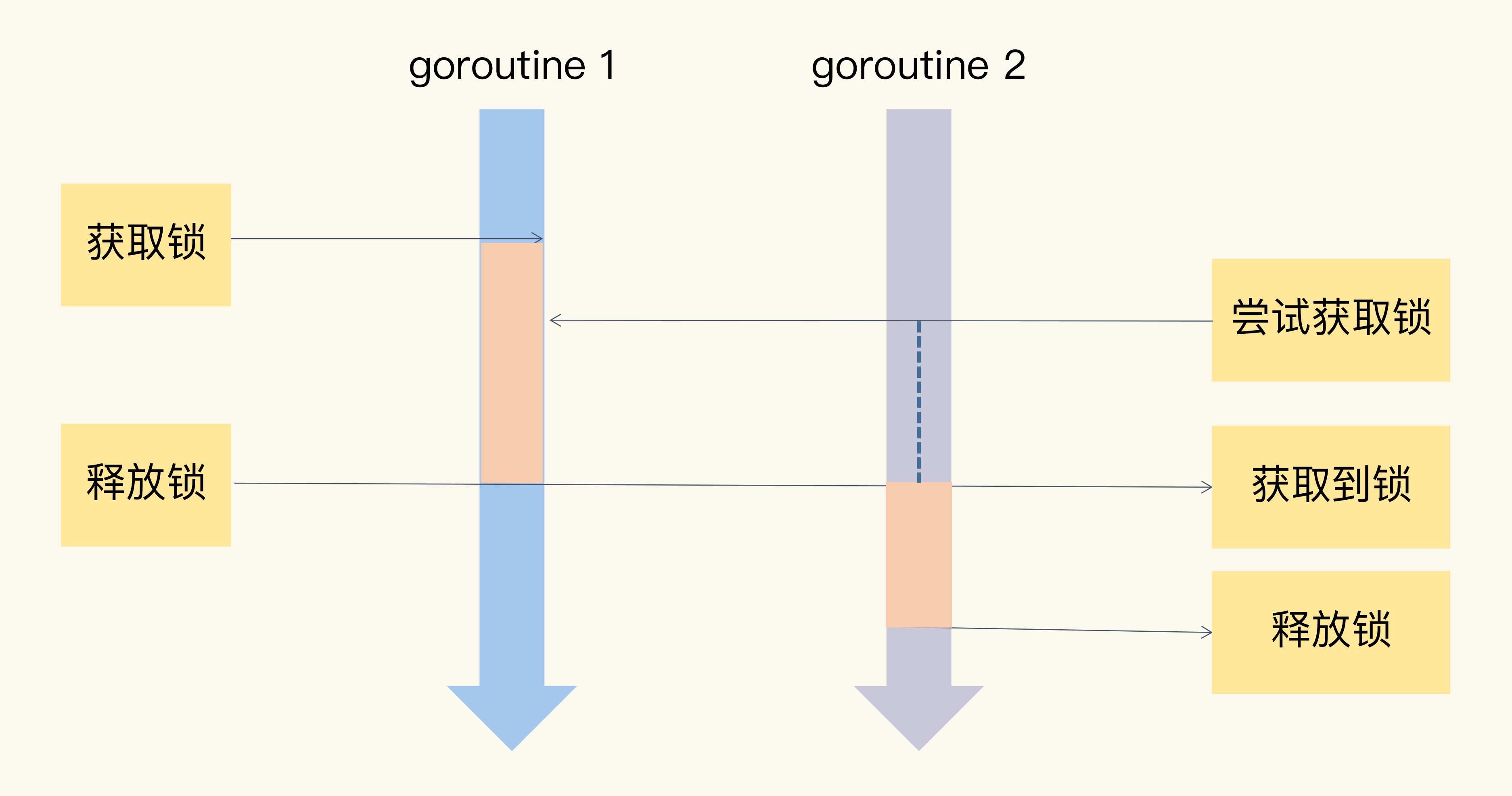
互斥锁可以很好地解决并发资源竞争问题。
Mutex基本使用方法
Go的标准库sync包提供了一系列的同步原语,还定义了一个Locker的interface,而锁继承和实现这个方法。
type Locker interface {
Lock()
Unlock()
}
interface秉承了Go语言一贯简洁的风格,提供了获取锁和释放锁两个方法。互斥锁Mutex和读写锁RWMutex都实现了这个接口。简单来说,互斥锁Mutex就提供两个方法Lock和Unlock:进入临界区之前调用Lock方法,退出临界区的时候调用Unlock方法。
当一个goroutine通过调用Lock方法获得了这个锁的拥有权后, 其它请求锁的goroutine就会阻塞在Lock方法的调用上,直到锁被释放并且自己获取到了这个锁的拥有权。
Mutex的零值是还没有goroutine等待的未加锁的状态,所以你不需要额外的初始化,直接声明变量(如 var mu sync.Mutex)即可。
思考题
你已经知道,如果Mutex已经被一个goroutine获取了锁,其它等待中的goroutine们只能一直等待。那么,等这个锁释放后,等待中的goroutine中哪一个会优先获取Mutex呢?
等待的goroutine们是以FIFO排队的。
- 当Mutex处于正常模式时,若此时没有新goroutine与队头goroutine竞争,则队头goroutine获得。若有新goroutine竞争大概率新goroutine获得。
- 当队头goroutine竞争锁失败1ms后,它会将Mutex调整为饥饿模式。进入饥饿模式后,锁的所有权会直接从解锁goroutine移交给队头goroutine,此时新来的goroutine直接放入队尾。
- 当一个goroutine获取锁后,如果发现自己满足下列条件中的任何一个:a.它是队列中最后一个。b.它等待锁的时间少于1ms。则将锁切换回正常模式。
2、Mutex的源码实现
如果你阅读Go标准库里Mutex的源代码,并且追溯Mutex的演进历史,你会发现,从一个简单易于理解的互斥锁的实现,到一个非常复杂的数据结构,这是一个逐步完善(提升性能和公平性)的过程。Mutex的架构演进分四个阶段,如下图所示:
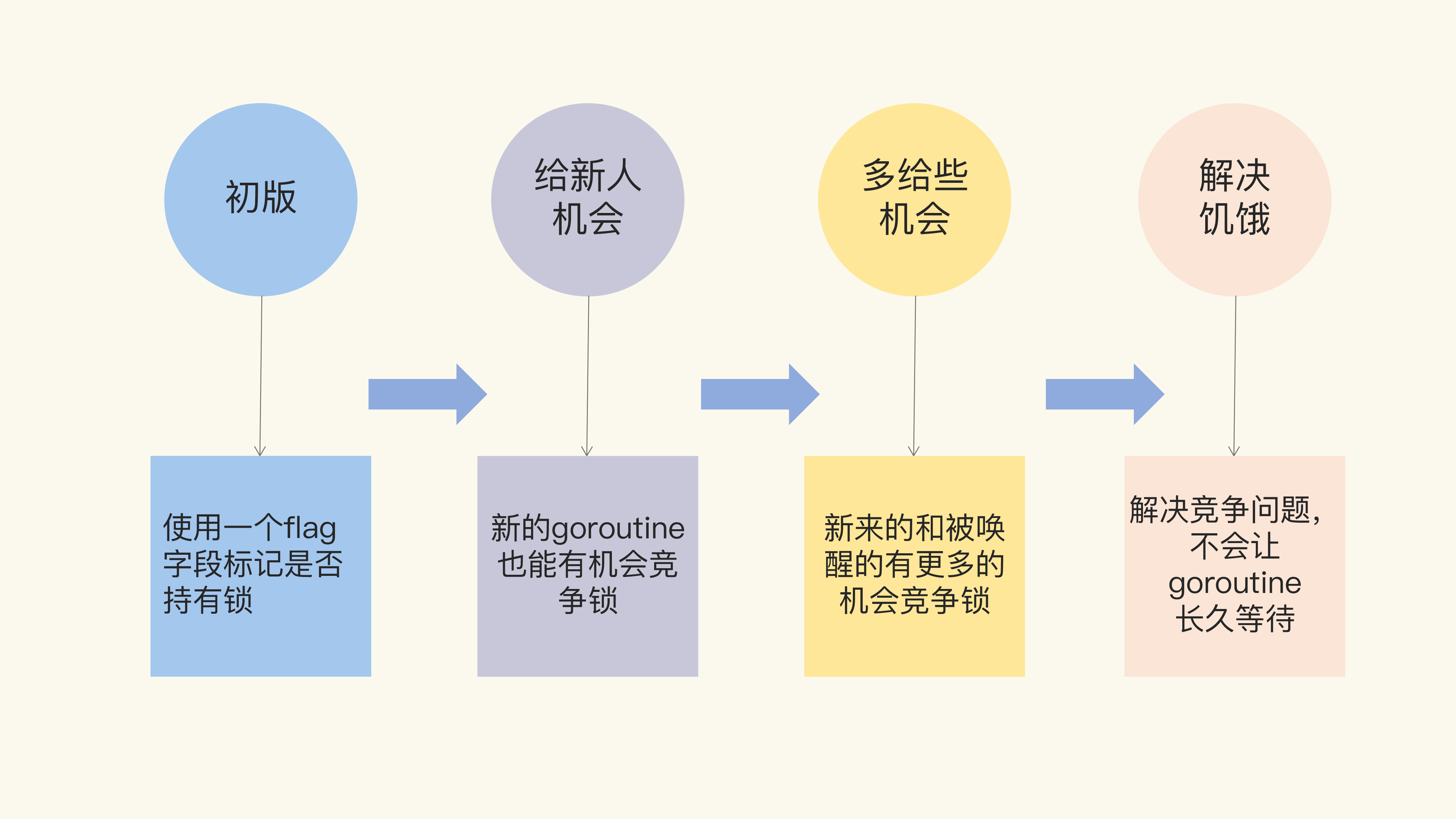
“初版”的Mutex使用一个flag来表示锁是否被持有,实现比较简单;后来照顾到新来的goroutine,所以会让新的goroutine也尽可能地先获取到锁,这是第二个阶段,我把它叫作“给新人机会”;那么,接下来就是第三阶段“多给些机会”,照顾新来的和被唤醒的goroutine;但是这样会带来饥饿问题,所以目前又加入了饥饿的解决方案,也就是第四阶段“解决饥饿”。
Go的atomic提供了一个原子操作,CompareAndSwap(CAS). CAS指令将给定的值和一个内存地址中的值进行比较,如果它们是同一个值,就使用新值替换内存地址中的值。原子性保证这个指令总是基于最新的值进行计算,如果同时有其它线程已经修改了这个值,那么CAS会返回失败。
初版的互斥锁
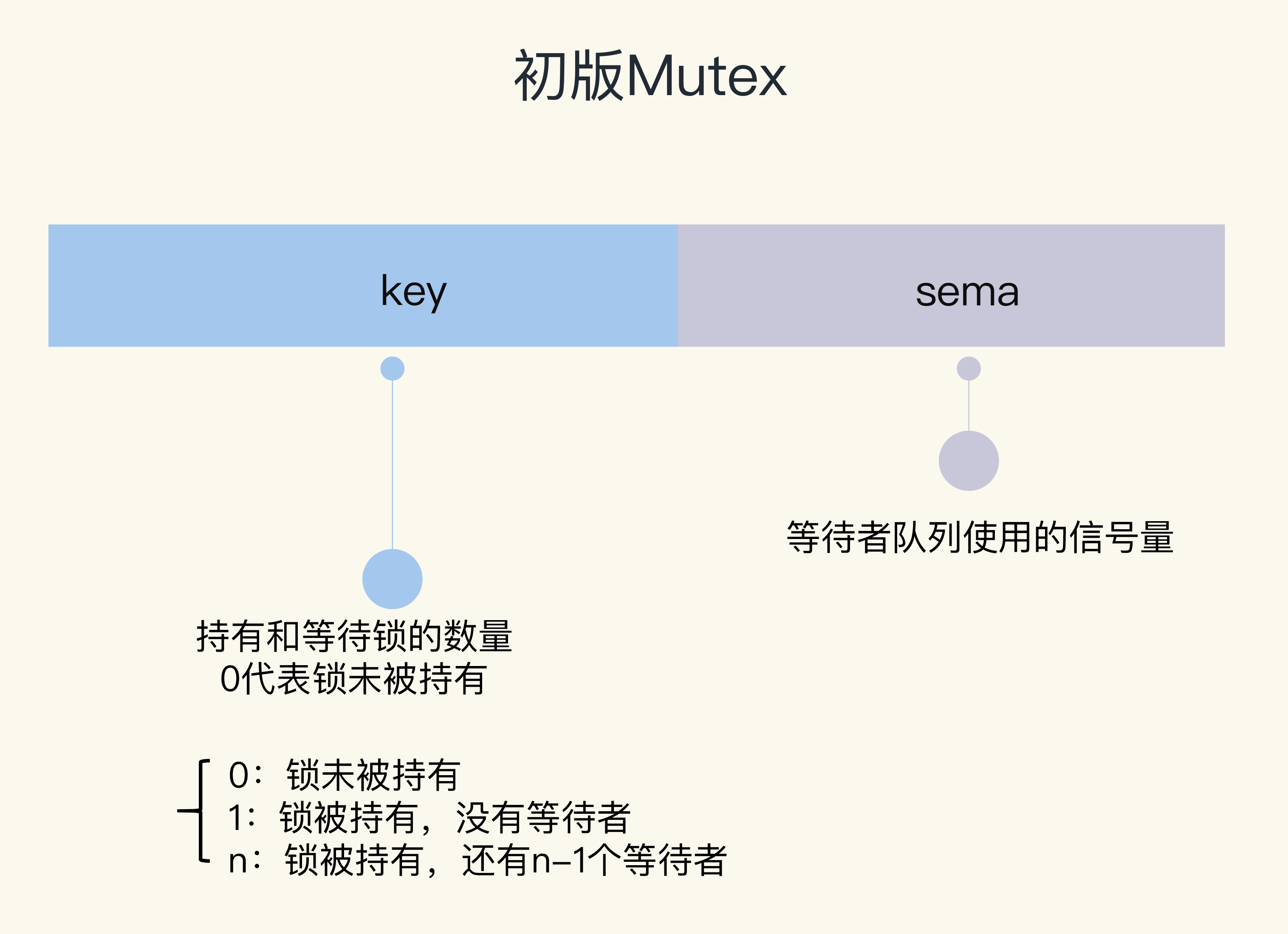
Mutex结构体包含两个字段:
- 字段key:是一个flag,用来标识这个排外锁是否被某个goroutine所持有,如果key大于等于1,说明这个排外锁已经被持有。
- 字段sema:是个信号量变量,用来控制等待goroutine的阻塞休眠和唤醒。
type Mutex struct {
key int32 // 锁是否被持有的标识
sema int32 // 信号量专用,用以阻塞/唤醒goroutine
}
Unlock方法可以被任意的goroutine调用释放锁,即使是没持有这个互斥锁的goroutine,也可以进行这个操作。这是因为,Mutex本身并没有包含持有这把锁的goroutine的信息,所以,Unlock也不会对此进行检查。Mutex的这个设计一直保持至今。如果锁被不正常的释放,那就会出现临界区资源同时访问的场景,从而锁的功能失败。所以,互斥锁必须严格遵守一个原则:谁申请,谁释放。否则就会出现问题,死锁或者锁失效。
采用defer的方式可以使Lock/Unlock总是成对出现。但是,defer也不是万能的,临界区只是方法中的一部分,为了尽快释放锁,还是应该第一时间调用Unlock,而不是一直等到方法返回时才释放,加大锁的范围会影响程序的并发能力。
顺便,关于defer,这边也记录一下。defer是在函数退出之前执行的runtime.deferreturn操作,defer其实一个个队列func操作,后面的func会在函数退出之前先执行。下面看一个defer的示例:
import "fmt"
func testClose(i int) {
fmt.Println("test_close", i)
}
func main() {
for i := 0; i < 2; i++ {
fmt.Println("call", i)
defer testClose(120 + i) //实际上要等main退出之后再defer,而defer的顺序是栈,即先入后出
}
fmt.Println("###########################")
for i := 0; i < 2; i++ {
func() {
fmt.Println("call", i)
defer testClose(150 + i) //当函数执行完成之后,立马做defer之后定义的操作,不需要等main函数退出
}()
}
}
输出结果如图:
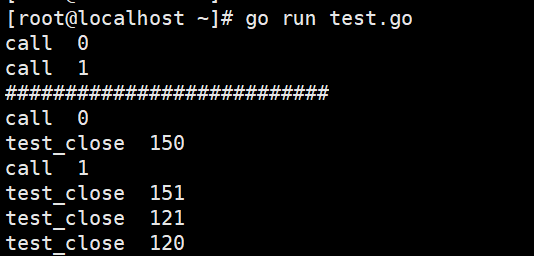
初版的Mutex实现有一个问题:请求锁的goroutine会排队等待获取互斥锁。虽然这貌似很公平,但是从性能上来看,却不是最优的。因为如果我们能够把锁交给正在占用CPU时间片的goroutine的话,那就不需要做上下文的切换,在高并发的情况下,可能会有更好的性能。
给新人机会
Mutex调整后的实现逻辑如下:
type Mutex struct {
state int32
sema uint32
}
const (
mutexLocked = 1 << iota // mutex is locked
mutexWoken
mutexWaiterShift = iota
)
第一个字段key被改成了state,且含义也不一样了,如下图:
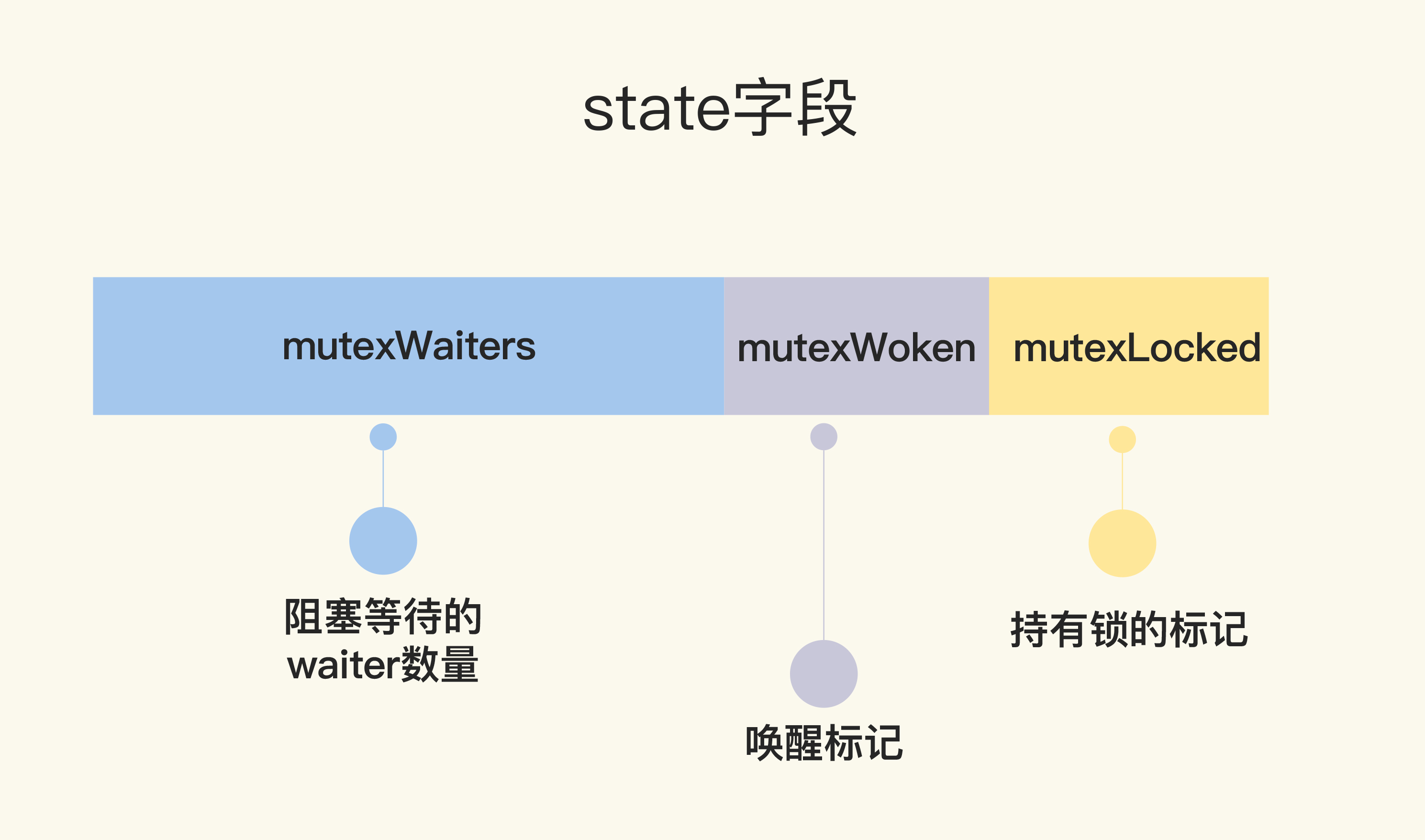
state是一个复合型的字段,一个字段包含多个意义,这样可以通过尽可能少的内存来实现互斥锁。这个字段的第一位(最小的一位)来表示这个锁是否被持有,第二位代表是否有唤醒的goroutine,剩余的位数代表的是等待此锁的goroutine数。所以,state这一个字段被分成了三部分,代表三个数据。