前言
Golang能够具备强大的并发能力,其核心秘诀就是goroutine协程以及通过调度器利用多核的能力,实现强大的并发支持能力。这一篇就来探索一下go调度器GMP的原理,了解并发背后真实的机制。
进程与线程
进程与线程的区别是什么?这是一个老生常谈的问题。处于不同层面对该问题的理解也不太一样。对于用户层面来说,进程就是一块运行起来的程序,线程就是程序里面一些并发的功能。对于操作系统来说,进程是资源分配的最小单位,而线程是CPU调度的最小单位。一个进程可以包含多个线程,线程共享进程拥有的内存空间,只有拥有了线程的的进程才会被CPU执行,所以一个进程最少拥有一个主线程。进程的切换要保存现场的寄存器、栈、代码段和执行位置等信息,而线程切换只需要上下文切换,保存线程执行的上下文即可,更加轻量级。进程面向的主要内容是内存分配管理,而线程主要面向的是CPU调度。
最早的系统,是串行的,一个CPU同一时间只能执行一个进程或者线程的任务,如果被阻塞,就只能等待。为了最大化利用CPU的能力,将CPU进行工作时间分片,执行完一个时间分片,立马切换到另一个线程。这样就会避免阻塞的问题,但是切换的CPU时间开销依旧被浪费了。同时,CPU需要针对线程设计线程调度器,负责协调多线程之间的同步资源竞争等问题。
协程
即使线程已经比较轻量化了,但是一个线程依旧要占M级的内存,面对海量高并发的场景,依旧会非常吃力。因此,线程被进一步细化为内核态的线程和用户态的线程,相当于两级线程。其中,用户态的部分也被称作协程。协程更加轻量级,由于协程是由用户创建的而非操作系统,所以处于用户栈能感知的范围,操作系统对它并没有感知。
为什么讲线程相对进程更轻量,而协程相对于线程更轻量。原因是线程能够共享进程的资源,包括:
- 内存地址空间
- 进程基础信息
- 大部分的数据
- 打开的文件
- 信号处理
- 当前工作目录
- 用户和用户组属性
而线程会独自拥有一些信息,包括:
- 线程ID
- 一系列的寄存器
- 栈的局部变量和返回地址
- 错误码
- 优先级等等
用户态的线程,协程也是共享线程的堆栈信息,存储的主要信息有:
- 执行时候的栈信息
- goroutine的状态
- goroutine的任务函数等等
简单的来说,其实就是线程只需要关注自己那部分的信息(也就是局部变量),而不需要关注共享的信息,协程也是一样的原理,所以才会更加轻量级。从进程到线程再到协程,其实是一个不断共享,减少切换成本的过程。
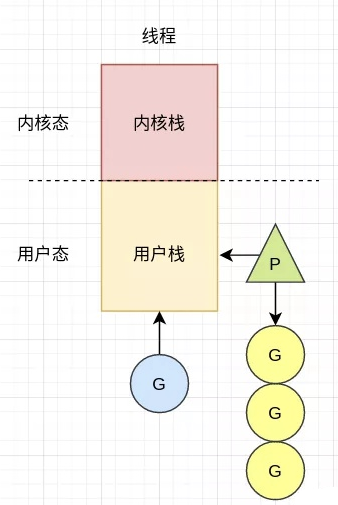
一个线程可以拥有多个协程,每个协程拥有自己的栈空间,协程切换只需要保存协程的上下文(在用户态切换),开销比内核态的线程切换要小很多,这种机制无疑给更大的并发提供了基础。因为CPU执行的最小单元就是线程,一个协程必须绑定一个线程,才可以被执行。协程可以和线程有多种映射关系,下面来分析一下每一种映射关系的情况。
1、多对一(N:1)
一个线程绑定多个协程(其实这里面有点狭义),指的是所有的协程都绑定在一个线程上。这样做的缺点显而易见:第一,程序用不了硬件的多核加速能力。第二,一旦某个协程阻塞,如果中间没有调度器来进行协调,那其他协程全部无法继续执行下去了。
2、一对一(1:1)
这种情况下,就相当于退化为全内核态线程了,协程和线程一对一,协程的创建、删除和切换全部交给CPU来完成,开销非常大。
3、多对对(M:N)
多对多的模式是上面两种方式的一种结合,符合实际并发场景的需要。线程由CPU调度,是抢占式的;而协程是由用户态调度,是协作式的。一个协程让出线程之后,才由其他的协程来占用。
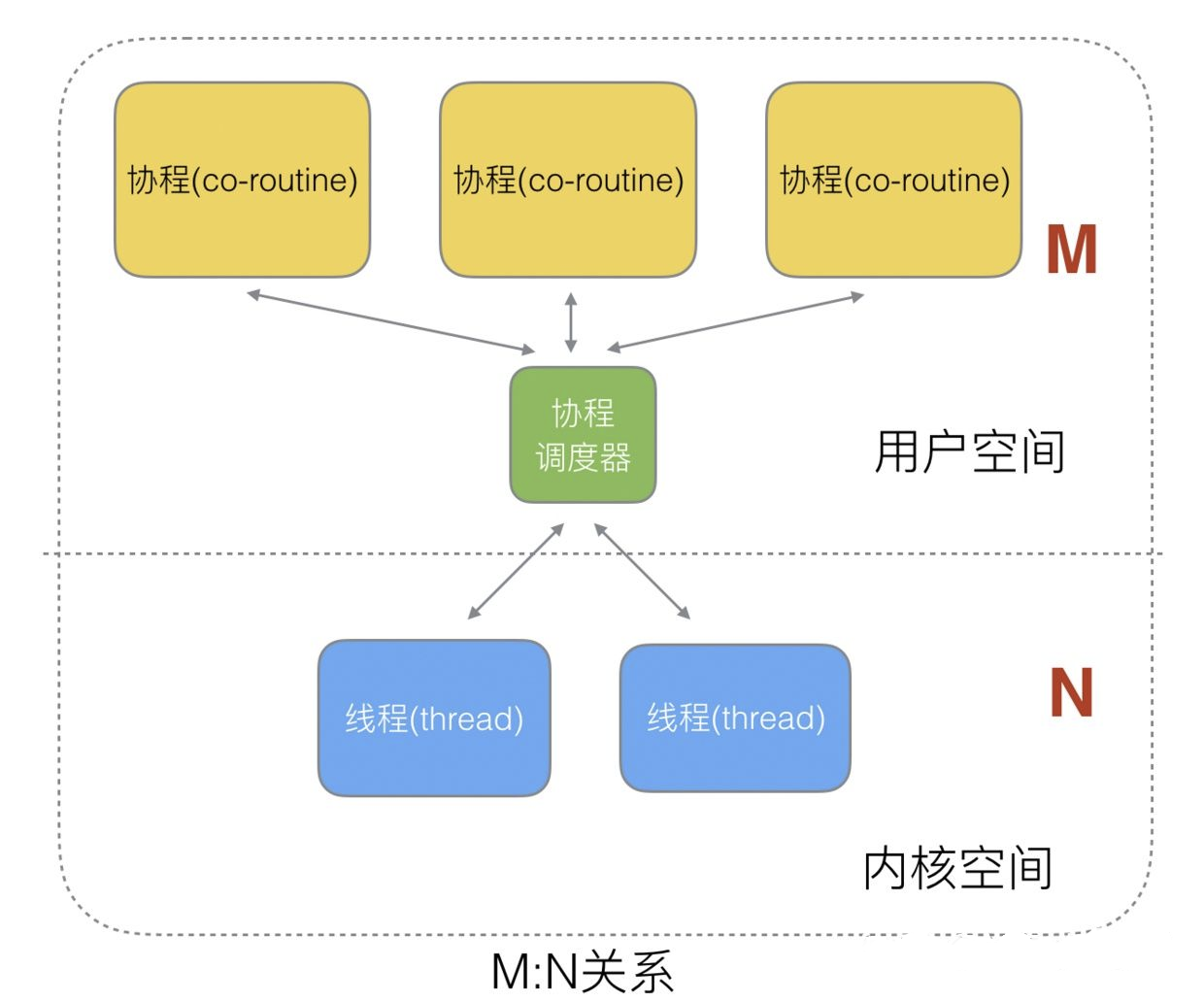
Goroutine调度器GMP
Go为了提供更容易使用的并发方法,使用了goroutine和channel。一个goroutine只占几个kb的内存,且依靠runtime可以实现灵活调度。那么我们就来看一下goroutine的调度器模型GMP是怎么运转的。首先是含义,GMP分别对应Goroutine/Thread/Processor,即协程、线程和调度器。
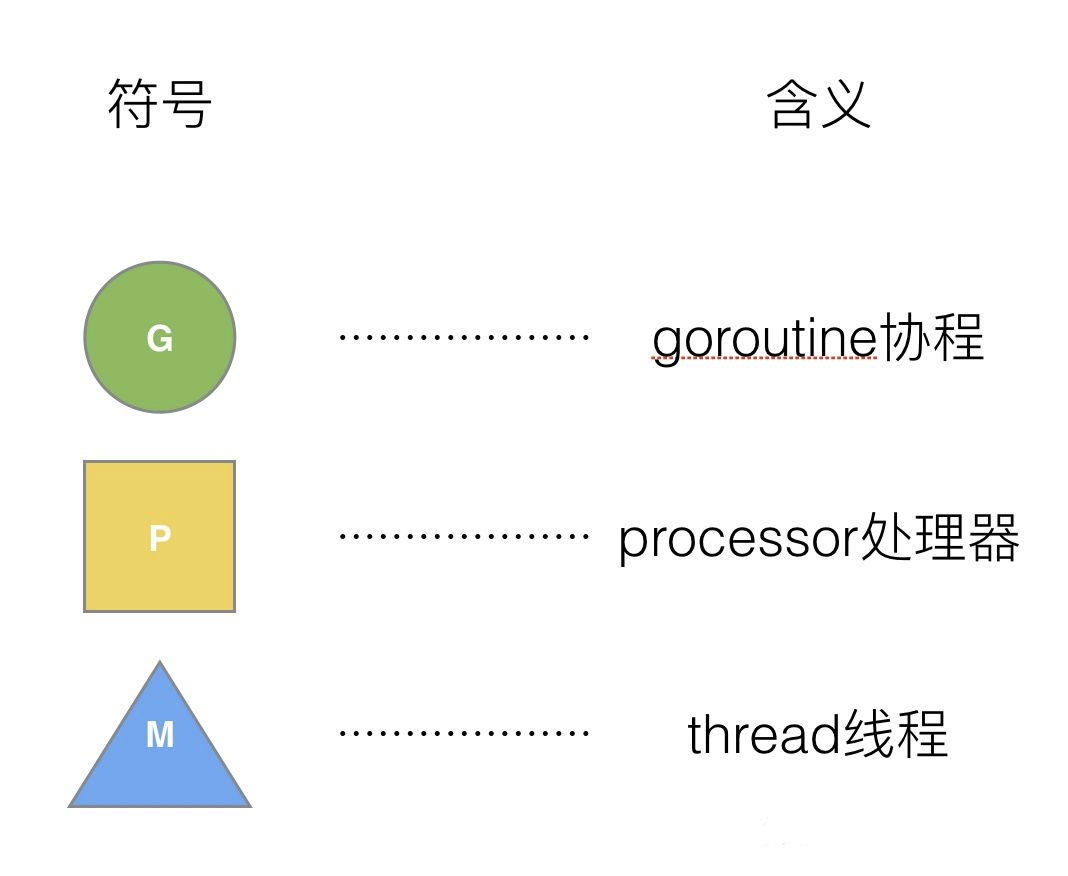
GMP模型
线程是运行goroutine的实体,调度器的功能是把可运行的goroutine分配到工作线程上,对于goroutine来说,P就是它的CPU。GMP模型的全局逻辑如下图所示:
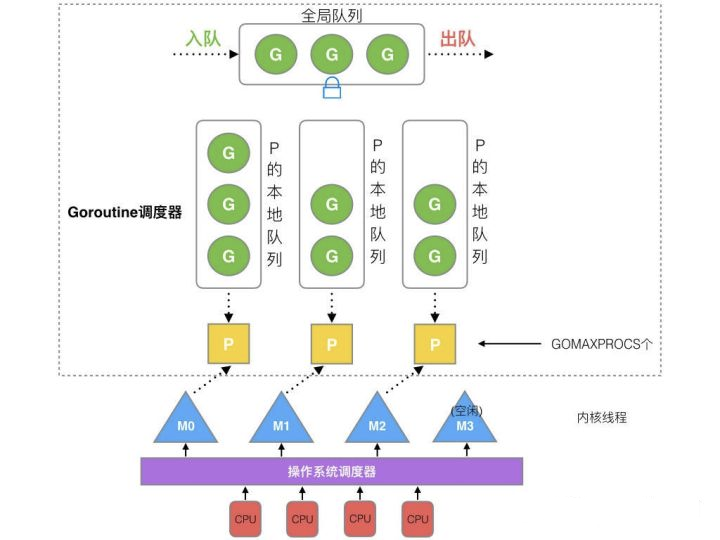
全局队列: 存放等待运行的Goroutine.
P本地队列: 同全局队列类似,存放的也是等待运行的Goroutine,存的数量有限,最多256个。当新建一个Goroutine的时候,会优先加入到P本地队列,如果队列满了,则会把本地队列中一般的Goroutine移动到全局队列。
P列表: 所有的P都在程序启动的时候创建,并保存在数组中,这个数量是可以配置的。
M(线程): 线程运行任务,获取P,然后从P的本地队列获取Goroutine,P队列为空的时候,M也会尝试从全局队列拿一批Goroutine放到P的本地队列,或者从其他P的本地队列偷取一半放到自己P的本地队列。M不断通过P获取Goroutine并执行,不断重复下去。M的数量最大默认是10000,但是内核很难支持这么多的线程数。如果M阻塞或者不够了,会创建新的M来支持。比如所有的M都被阻塞住了,而P中还有很多的就绪任务,调度器就会去寻找空闲的M。找不到的话,就会去创建新的M。
Goroutine调度器负责协程把协程分配给线程,而OS调度器负责把内核线程分配到CPU的核上执行,整个过程由两个调度器结合完成。
调度器的设计策略
- 复用线程:线程并不是用完即销毁,会被复用,避免频繁的创建和销毁线程的开销。
- work stealing机制:当本线程无可运行的Goroutine时,尝试从其他绑定的P队列偷取Goroutine,而不是销毁线程。
- hand off机制:当本线程因为Goroutine进行系统调用阻塞时,线程释放绑定的P队列,把P转移给其他空闲的线程执行。
- 并行:多个线程分布在多个CPU上同时运行。
- 抢占式调度:限制Goroutine占用CPU的时间(比如10ms),防止其他Goroutine被饿死。
- 全局队列:全局队列相当于一个二级全局缓存,在已经有本地队列缓存的情况下,防止本地队列缓存数量过大。
关于M0和G0的设计:M0是启动程序后编号为0的主线程,这个M对应的实例会在全局变量runtime.m0中,不需要在heap上分配,M0负责执行初始化操作和启动第一个Goroutine,在之后M0就和其他M一样了。G0是每次启动一个M都会第一个创建的Goroutine,G0仅用于负责调度Goroutine,不指向任何可执行的函数,每个M都会有自己的G0。在调度或者系统调用时会使用G0的栈空间,全局变量G0是M0的G0.更详细的说明:
- m0表示进程启动的第一个线程,也叫主线程。它和其他的m没有什么区别,要说区别的话,它是进程启动通过汇编直接复制给m0的,m0是个全局变量,而其他的m都是runtime内自己创建的。m0的赋值过程,可以看前面 runtime/asm_amd64.s 的代码。一个go进程只有一个m0。
- 首先要明确的是每个m都有一个g0,因为每个线程有一个系统堆栈,g0虽然也是g的结构,但和普通的g还是有差别的,最重要的差别就是栈的差别。g0上的栈是系统分配的栈,在linux上栈大小默认固定8MB,不能扩展,也不能缩小。而普通g一开始只有2KB大小,可扩展。在g0上也没有任何任务函数,也没有任何状态,并且它不能被调度程序抢占。因为调度就是在g0上跑的。
Go调度器调度场景过程全解析
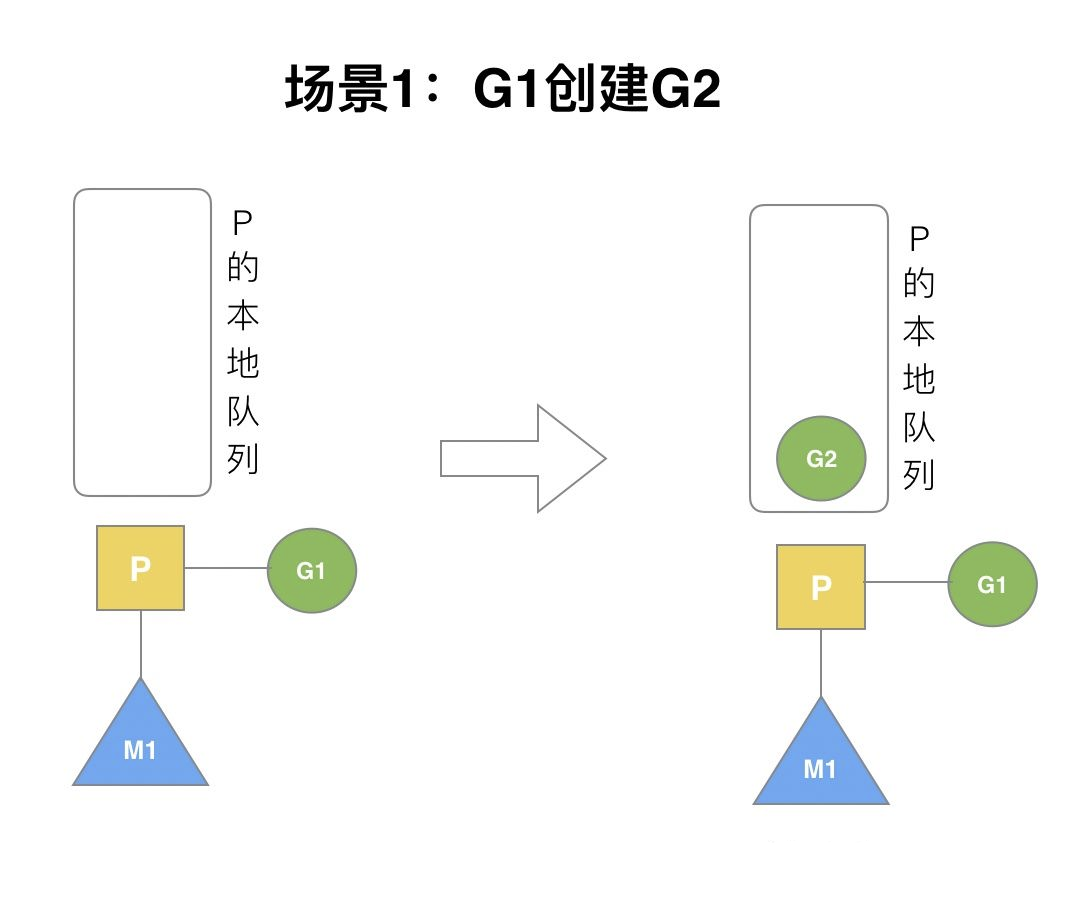
场景1
P拥有G1,M1获取P之后开始运行G1,G1使用go func()创建了G2,G2会优先加入到P1的本地队列,如图所示:
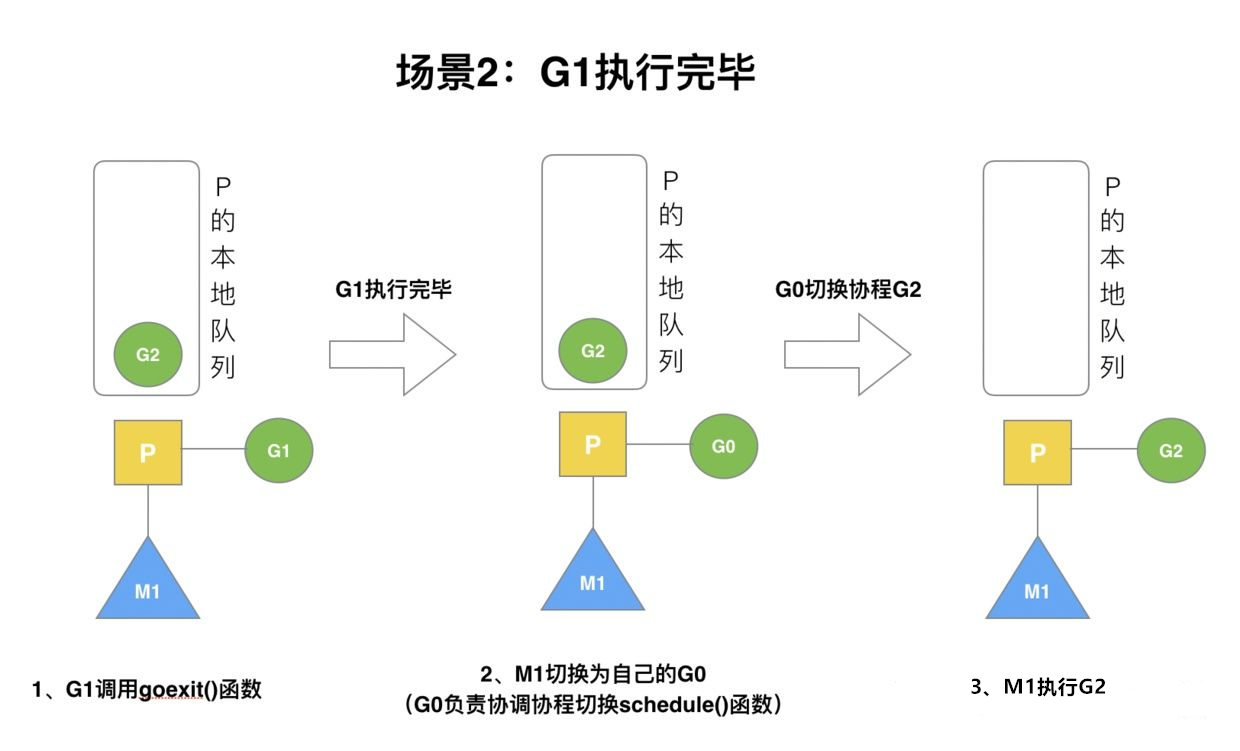
场景2
G1运行完成后退出后(goexit),M上运行的goroutine切换为G0,G0负责调度时协程的切换(schedule)。从P的本地列表获取G2,从G0切换到G2,并开始运行G2(excute)。实现了对线程M1的复用。
场景3
P的本地队列存储的G有限,新开辟的G如果过多,则会把本地队列塞满,如下图所示:
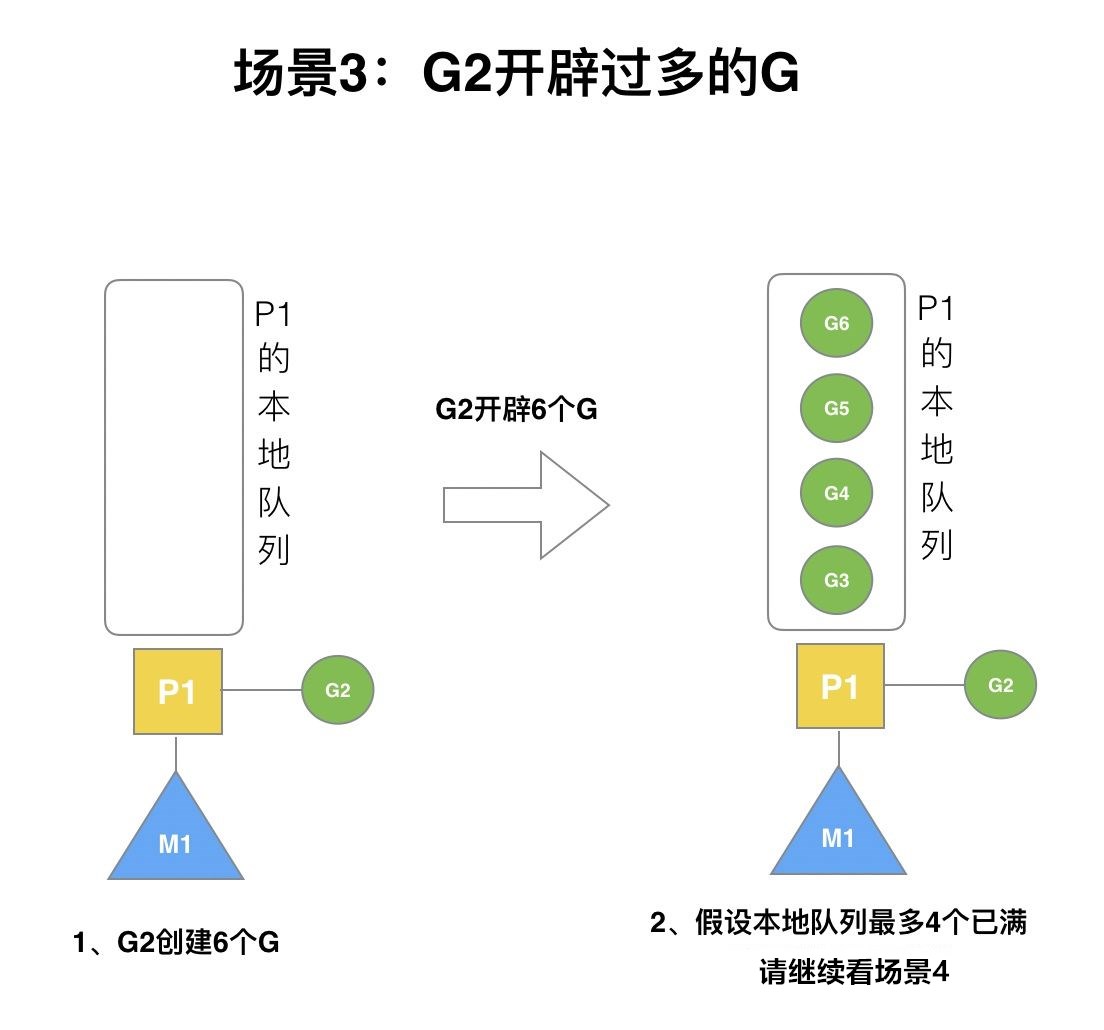
这个时候,已经溢出的G就需要额外的空间来存储,接下来我们继续看场景4.
场景4
G2在创建G7的时候,发现P1的本地队列已满,需要执行负载均衡,把P1中本地队列的前一半和新创建的G(不一定是新创建的G,如果G是在G2之后就执行的,则会被保存在本地队列中)转移到全局队列。如图所示:
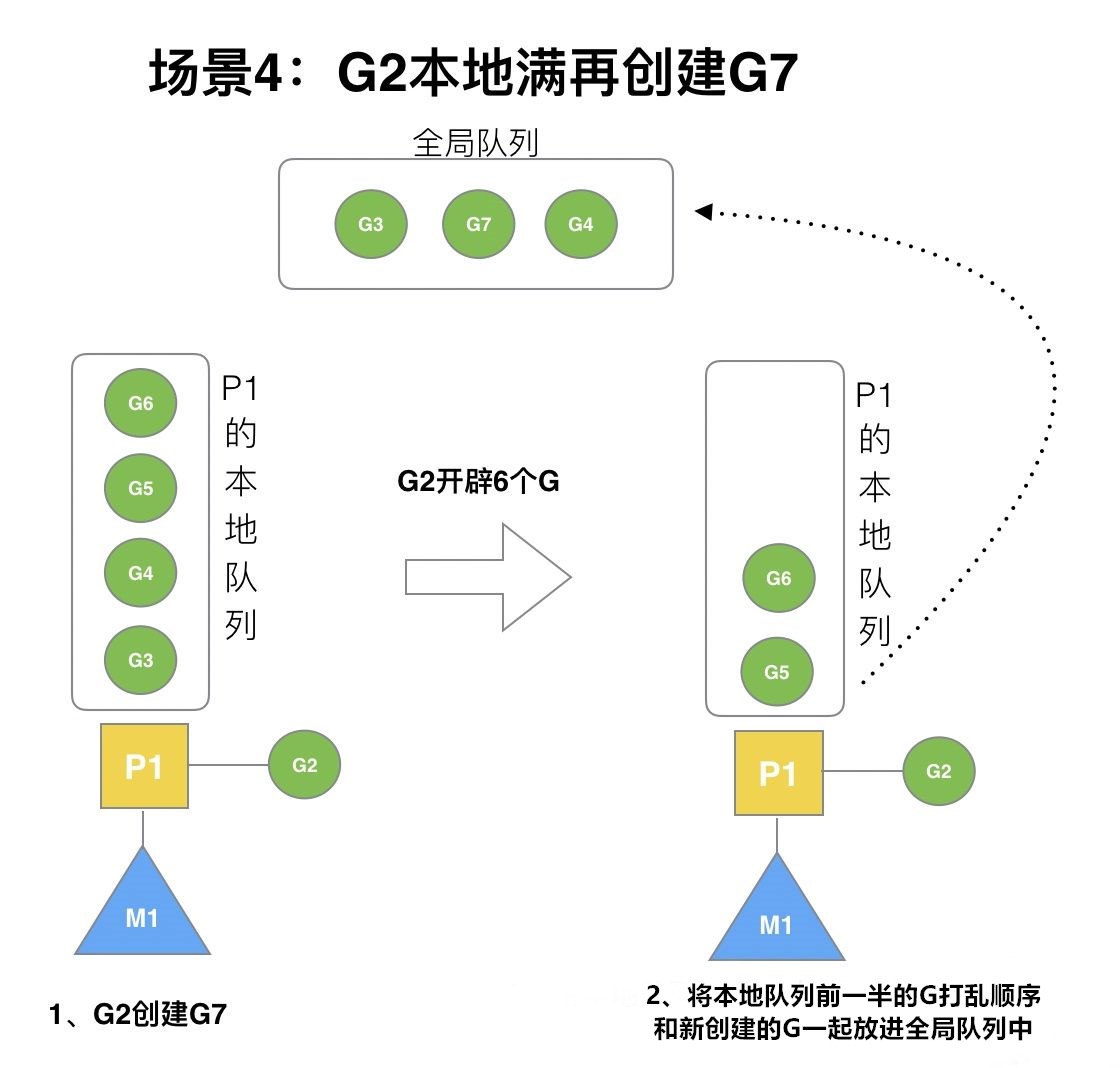
这些G被转移到全局队列时,会被打乱顺序。
场景5
G2创建G8时,P1的本地队列未满,因此G8会被加入到本地队列。
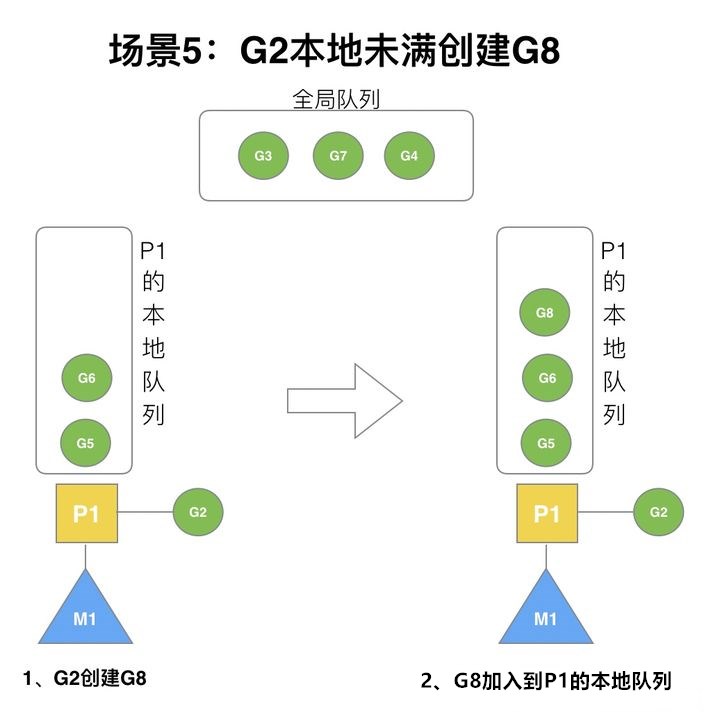
G8加入到P1本地队列的原因是因为P1此时在与M1绑定,而G2此时是在M1执行。所以G2创建的新的G会优先放置到自己的M绑定的P队列上。
场景6
当全局队列有G未消费时,运行的G会尝试唤醒其他空闲的P和M组合。
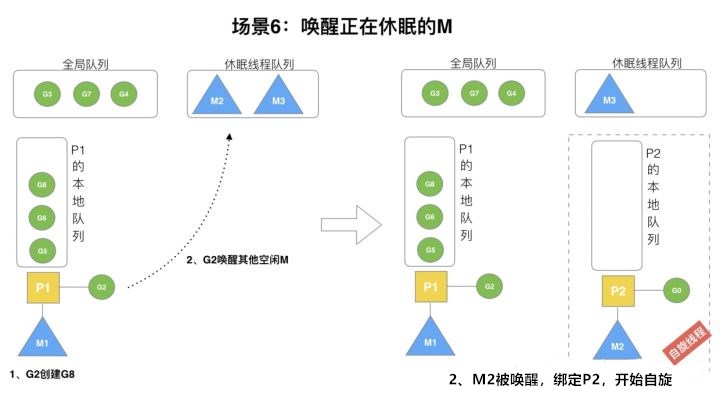
假定G2唤醒了M2,M2绑定P2,并运行自己的第一个Goroutine-G0。但P2的本地队列还没有G,M2此时为自旋状态(没有G且状态为运行中的线程,不断寻找可执行的G)。
场景7
空闲的M2线程尝试从全局队列(简称GQ-global queue)取一批G放到P2的本地队列(函数:findrunable())。M2从全局队列取的G数量符合下面的公式:
n = min(len(GQ)/GOMAXPROCS + 1, len(GQ/2))
意思是至少从全局队列里面取一个G到本地运行,GOMAXPROCS对应的是P的数量。也不能一次从全局队列拿太多的G到本地,要充分利用多核的优势,实现对G运行的负载均衡。
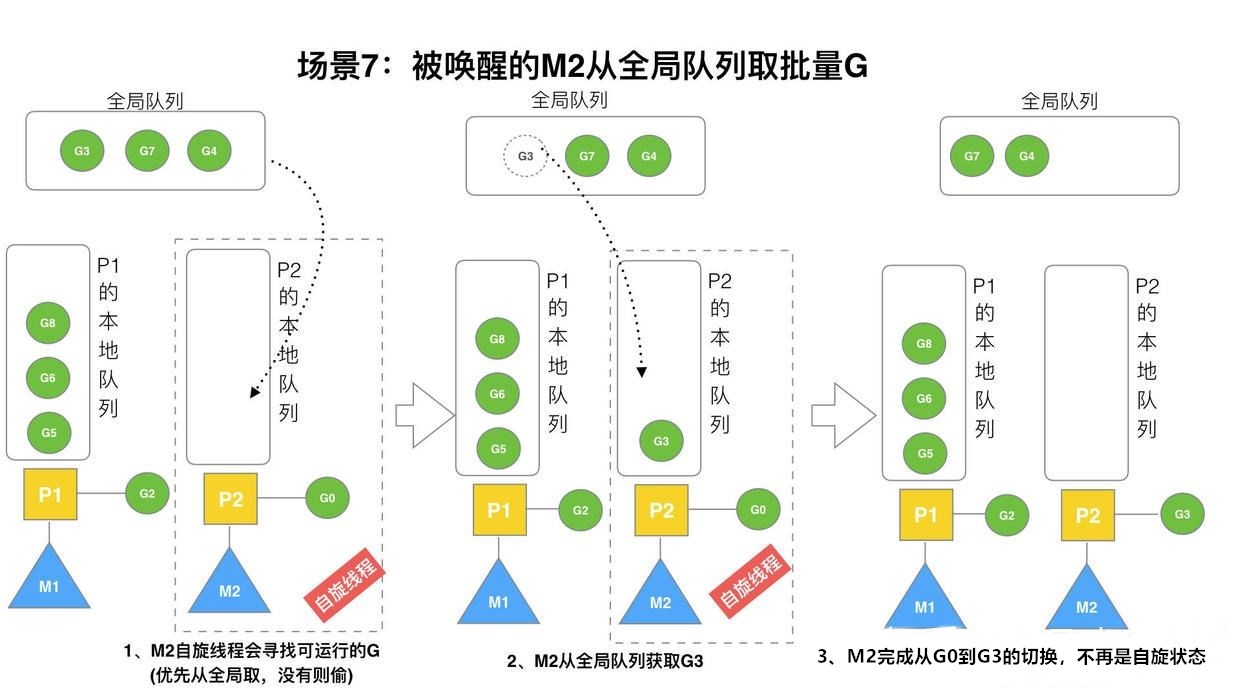
拿到G的M,完成从G0到实际的G的切换,开始运行G(图中为G3)。
场景8
假设G2一直在M1上运行,运行时间很长。经过几轮之后,M2已经把从全局队列获取到本地队列的G全部运行完了。这时候,全局队列和P2本地队列全部为空,如下图的左半部分。
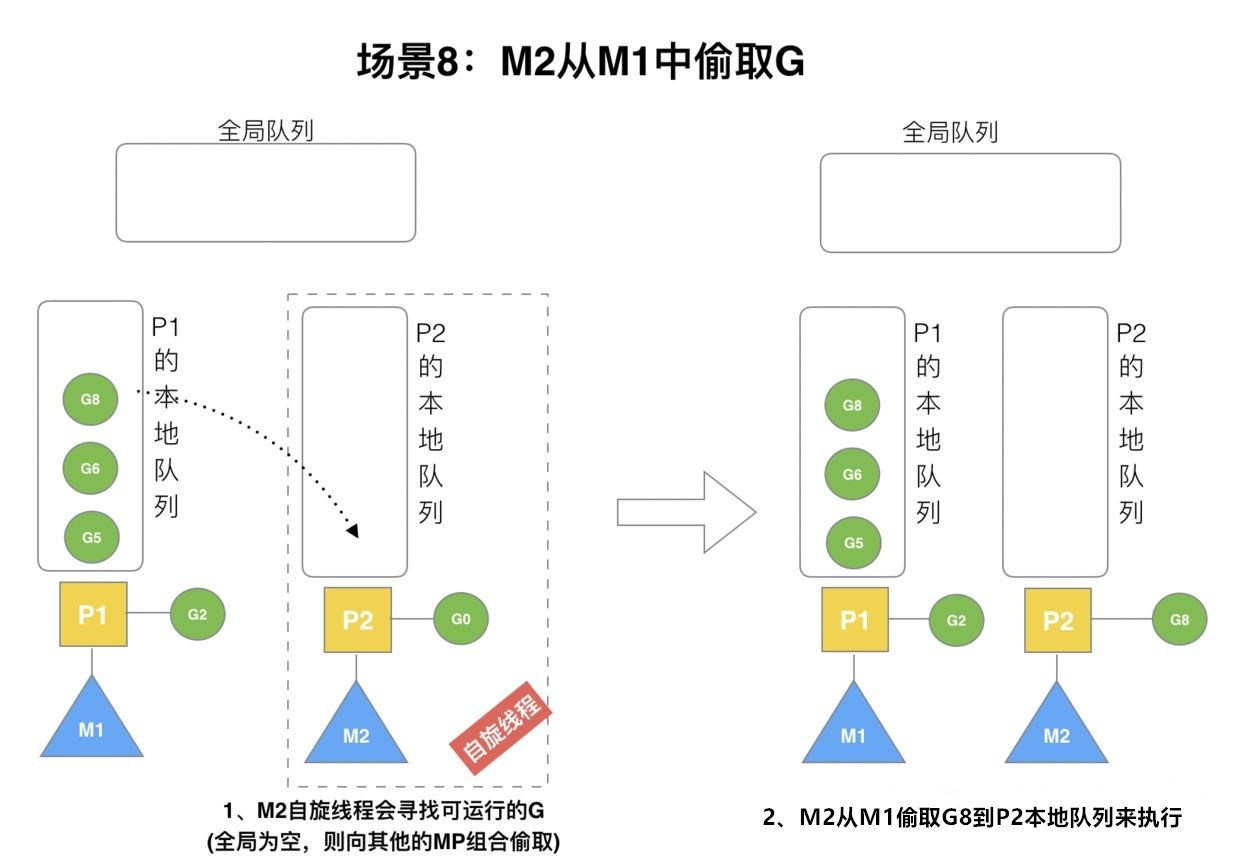
空闲的M不会立马进入休眠模式,而是会执行work stealing从其他P的本地队列偷取一半的G(图中偷取3个中的一个:G8)放到自己的本地队列,然后开始执行。
场景9
P1本地队列的G已经被其他M偷走并运行完成,M1和M2分别运行G2和G8,M3和M4没有goroutine可以运行,转为自旋状态,不断寻找新的goroutine。
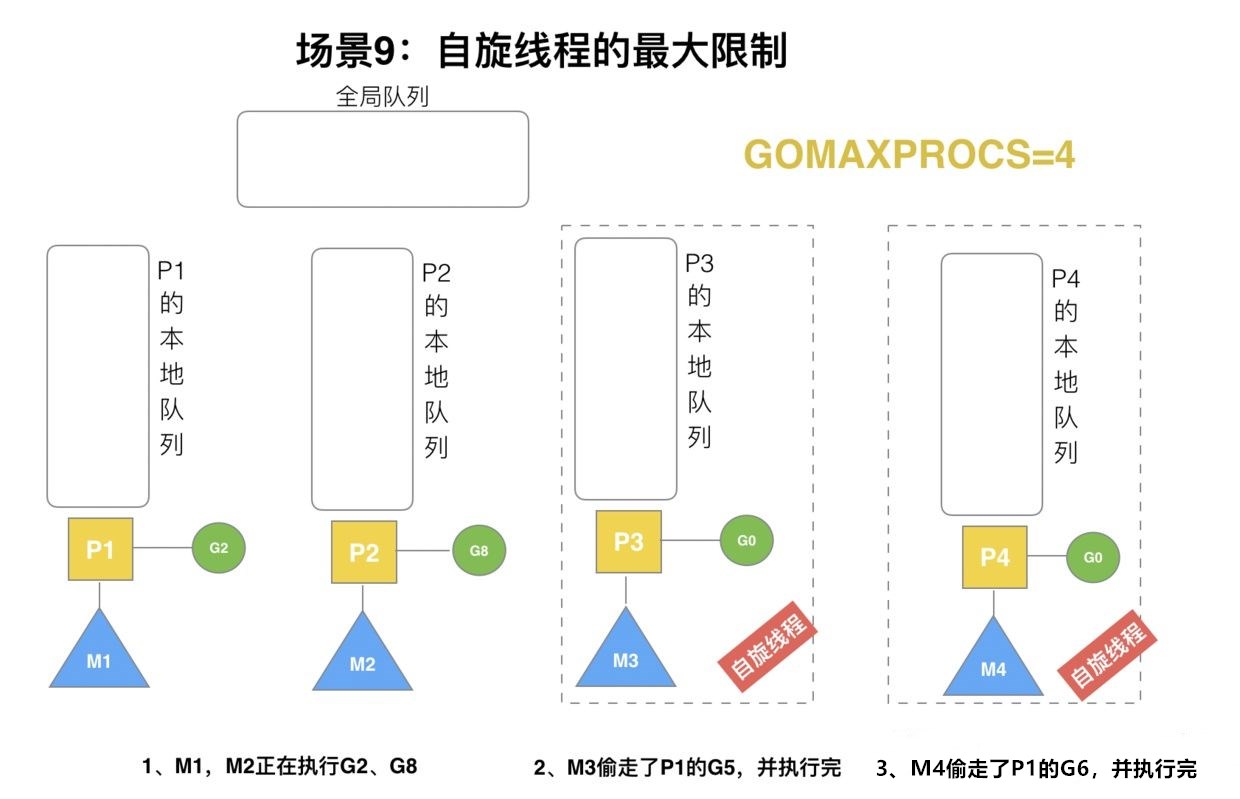
自旋本质上也是在运行,线程在运行却没有执行G,也会浪费CPU。但是销毁线程也不一定会节约CPU资源,创建和销毁CPU也会消耗CPU。自旋的目的是,当有新的goroutine来的时候,立刻能有M运行它。M如果已经处于自旋,那当然是没必要在设置为自旋状态,主要关注另外一个条件,当正在自旋的M的个数的2倍大于等于正在忙的P的个数时,不要让该M自旋。这是为啥?注释上解释说为了避免CPU的过多的消耗。毕竟自旋是需要消耗CPU的,如果已经有不少的P处于忙时,应该尽量让P去占用CPU资源,而不是为了查找G而浪费CPU。当然一旦自旋的M找到G后,就会自动退出自旋状态。如果一个M找不到工作,又没有进入自旋状态,那么会调用stopm 来休眠该M,并且会将P和M解绑,那何时会重新唤醒该M呢?这就要看wakep函数了。一般来说新建一个goroutine或者有个goroutine准备好时,会调用wakep来唤醒M或者新建M
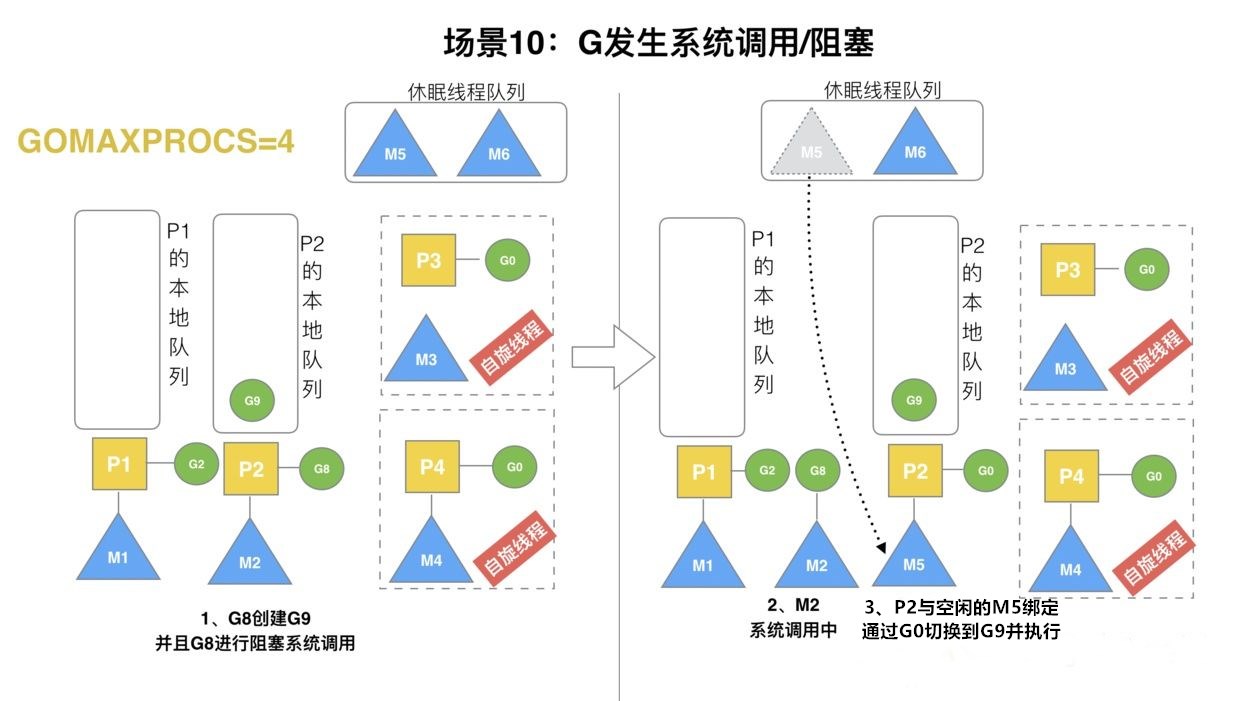
场景10
当前除了M3和M4为自旋线程,还有M5和M6为空闲的线程,M的数量大于等于P。G8创建了G9,然后G8的运行遇到了阻塞的系统调用。这个时候,P1队列中等待运行的G9就会被卡住。因此,P2立马和M2解绑,P2会执行一下判断:如果P2本地队列有G、全局队列有G或者有空闲的M,P2会立马唤醒一个M和它绑定,否则P2会渐入空闲P列表,等待新的M。在本场景中,P2本地队列有G9,因此P2和空闲线程M5绑定,并把G9拿过来执行。
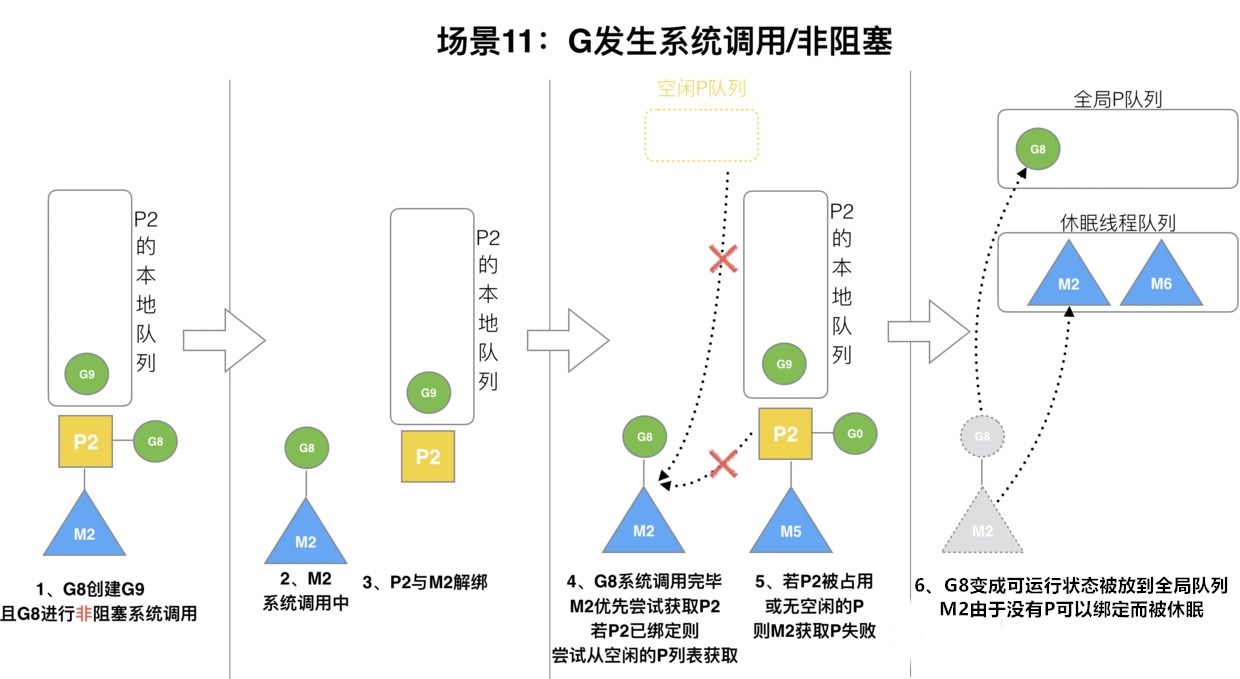
场景11
接上个场景,当G8的系统调用非阻塞之后,M2和P2已经解绑了,但是M2会记住P2,并尝试重新获取和绑定P2。如果获取不到P2,则尝试获取空闲的P,空闲的P也没有的情况下,G8会被标记为可运行状态,并加入到全局队列,M2因为没有P绑定而变成休眠状态。那些长时间休眠的M会被GC回收,后面我们会专门开一篇来看Go的垃圾回收原理。
总结
Go的调度器也是轻量的,GMP的机制让Go具有了原生强大的并发能力。Go调度本质上是把大量的go协程分配到少量的线程上去执行,并利用多核并行,实现更强大的并发。